
Decentralized Domain Ownership
A couple of years ago, Forrester Research identified a new type of organization, coined the Insights-Driven Business, a business characterized by making fact based decisions supported by data. To accomplish this, companies undertook a journey to make their data increasingly available across the organization. Why? Simple; insights cannot be planned for.
The goal for any Insights-Driven Business is to instill a culture of data literacy across the organization, making data intrinsically available for later use. This “data culture” adoption has taken a similar trajectory to that of DevOps, with reports coming out about how companies are failing to make this adoption.
How did we get here?

To make data-based decisions, we need to connect data producers with data consumers. Data producers are typically those in charge of data producing systems. They have domain expertise in a particular area, can be in charge of data quality, and can exert some control over how the data is shaped for consumption. Meanwhile, data consumers, are interested in data across the organization. They can be data scientists, looking for patterns in the data, or data application owners, who work to serve/present data in meaningful ways.
Traditionally, companies adopted a Business Intelligence (BI) approach for making business decisions with these solutions centralizing data within a data warehouse. Data warehousing technology, relying heavily on structured data representations such as SQL, brought a type of inflexibility to the use of the data. This was ultimately because data warehousing patterns require aligning source data to some pre-defined schema at ingestion time.
From an enterprise architecture perspective, what companies really needed to achieve (to become insights-driven) was a separation of roles between data producers and data consumers. As a result, the data lake was born.
In the data lake pattern, data producers can focus on making data available (in a consumable format) to the business. When producing data, the producers are not constrained by future consumption patterns. This means a variety of data can be shared, not just that which fits in table formats. Transforms and insights can be created at a further stage in the pipeline.
Decentralized Domain Ownership

In an article on the concept of data mesh, the author discusses the concept of decentralized domain ownership. In this strategy, data is refined (or made available) via the concept of domains, these domains can then be combined to further derive value. Domains can build upon each other, initially oriented around source data, progressing toward consumer oriented data. In each stage, a different set of expertise may be required to repackage the data in meaningful ways.
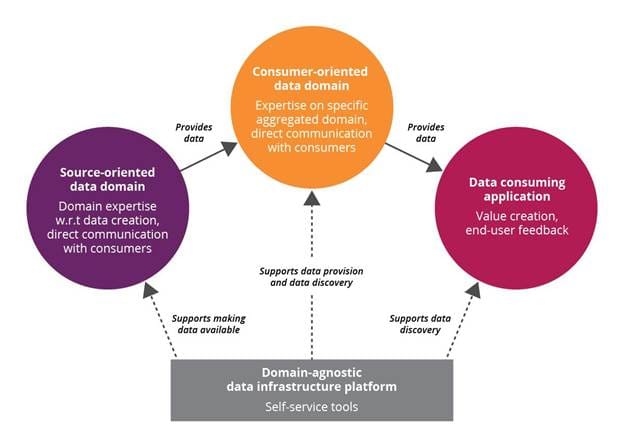
Because these data domains are fluid and flexible, care should be taken to keep the infrastructure domain-agnostic, making sure:
- Data can be stored in domain specific storage containers, geo-located as required
- New data domains can be created without friction
- Identity and access can be enforced across the platform
How Daturic supports an insights-driven business

A core design philosophy behind Daturic is to support a decentralized domain ownership model. We make it easy for data producers to create data lake structures for storage and discovery. These structures can be easily combined, via tagging and policies, in meaningful ways to drive insight-based decisions. Protections within the Daturic system ensure that data producers only need focus on creating data for consumption, access grants are still controlled via your existing corporate control mechanisms. This separation of duties allows organizations to ensure security decisions are governed appropriately, while allowing the data experts the ability to group data access in meaningful ways.
With Daturic you can:
Register your data across multiple containers. The Daturic platform can work across many data lakes. Create domain specific data storage and register it in the system to be used with our tags and policy engine. This allows your data producers to meet their isolation and control needs while making your data packages accessible across your organization.
Make only the data you want available. Daturic is not an all or nothing solution; it is designed to work in existing data scenarios. Register your data lakes and manage only the data structures you want within them. This flexibility gives you options to leave your data creation processes un-touched, while allowing your curated data packages to be made available with common access controls.
Embrace the dynamic nature of your data. Daturic allows you to evolve your data packages over time. By using the intuitive tagging system to tag new data as it becomes available, Daturic will automatically recalculate and apply your access control settings, providing data consumers fast access to the data they need.
Enforce security at the edge with strong identity tie-ins. With the Daturic system, your data isn’t travelling through a third party with access control being enforced by a proxy. Rather, our policies crystalize the access control policies directly on the data lakes. Your security is enforced where your data is stored.